
Zookeeper Tutorial (Step 3 on 4)
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Zookeeper is useful if you would like to secure your architecture a little more and prevent from the consequences of the fall of your Masters for example.
Zookeeper (ZK) may be installed on its own on a node, or together with Spark/Cassandra on a worker node. Each ZK node should be aware of other ZK instances in order to form a quorum of 3. We chose to install zookeeper before Spark since the configuration is lighter.
1. Conexion SSH on the Slave nodes 1 & 2 and Zookeeper node
The first step is to establish a SSH connection with the nodes on which you would like to install Zookeeper. If you don’t remenber how to do that, you can check the last section of my first tutorial :
AWS EC2 Instances Tutorial (Step 1 on 4)
2. Go on Apache-Zookeeper’ Website
You need to copy the link to donwload Apache-Zookeeper.
Zookeeper’ Website for version 3.4.13
3. Install Apache-Zookeeper on your instances
Make sure your on the /ubuntu/home/ directory.
a. Download the .tar.gz file :
Ones your in the good directory, execute the following command :
$ wget https://www-eu.apache.org/dist/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
You will see something like this :

b. Extract the software :
You need to extract the software by executing the command bellow : tar -xv zookeeper-3.4.13.tar.gz
Just after, remove the .tar.gz file :
rm zookeeper-3.4.13.tar.gz
Your terminal of your nodes 1 & 2 looks like :

c. Do it on each nodes
Execute the same commands in order.
5. Configuration of your three nodes
For our tutorial, we need to :
- modify
zoo-sample.cfg - modify
spark-default.sh(this is for the next tutorial) - rename the directory
zookeeper-3.4.13 - create the directory
logsanddata - create a file
myidin the newdatadir
a. Rename directory :
Make sure your on the /ubuntu/home/ directory.
Execute the following command :
mv zookeeper-3.4.13/zookeeper_1
Put the digit :
- 1 if it’s your Worker node 1
- 2 if it’s your Worker node 2
- 3 if it’s your Worker node named ‘Zookeeper’
b. Create the directory logs and data :
Now, you need to create those 2 new directories :
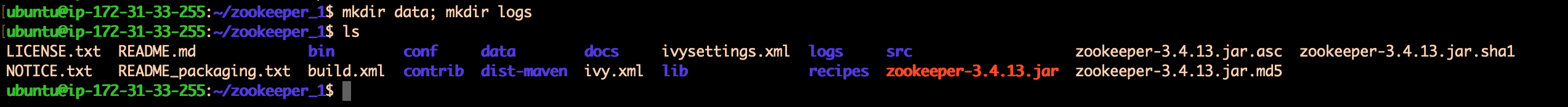
c. Create a new file myid :
Go on the new directory data and create a new file which contains only a digit between 1 and 3.
Put the digit 1 if it’s your Worker node 1
2 if it’s your Worker node 2
3 if it’s your Worker node named ‘Zookeeper’
Example :

d. Modify zoo-sample.cfg :
First, make sure your on the conf directory.
Copy the file zoo-sample.cfg as zoo.cfg.
Use this command :
cp zoo-sample.cfg zoo.cfg
Now, we will change which is inside ‘zoo.cfg’ file :
vi zoo.cfg
We will change :
clientPort= 218X(The X is a digit between 1 and 3 –> 3 because we have 3 nodes with Zookeeper) –> refer to section 5.c. to know which digit you need to put.- add :
server.1=<PRIVATE.DNS.1>:2891:3881 ; server.2=<PRIVATE.DNS.2>:2892:3882 ; server.3=<PRIVATE.DNS.3>:2893:3883 - datadir=
<Path to the data dir>
Example :
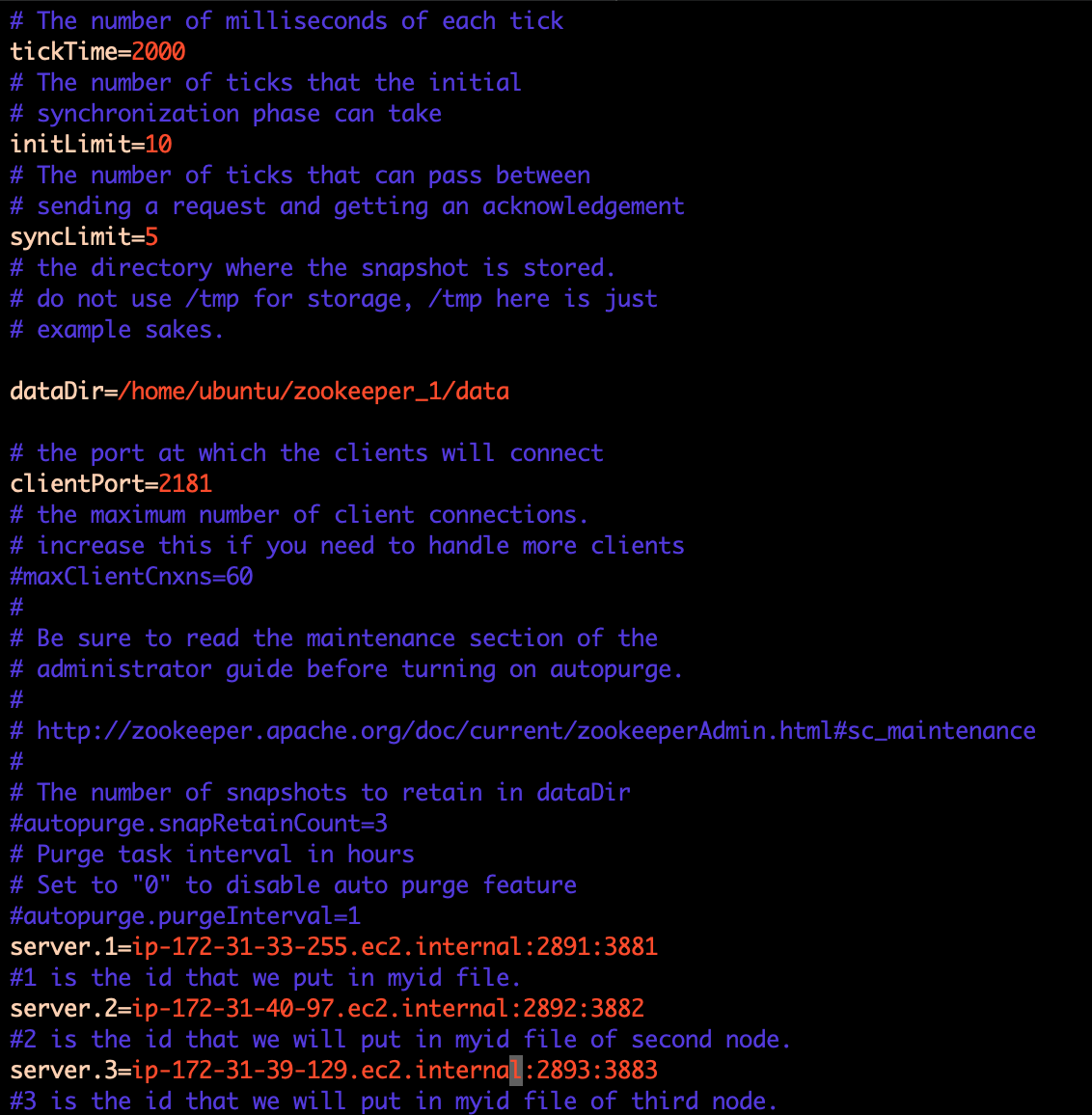
Save and quit.
e. Copy some files :
Go on the home directory (zookeeper_X) and execute this :
java -cp zookeeper-3.4.13.jar:lib/log4j-1.2.17.jar:lib/slf4j-log4j12-1.7.25.jar:lib/slf4j-api-1.7.25.jar:conf org.apache.zookeeper.server.quorum.QuorumPeerMain conf/zoo.cfg >> logs/zookeeper.log &
Repeat those steps on the three nodes. Do not forget that you need “OpenJDK-8” on each nodes.
We discussed how to set up an ensemble with 3 nodes. Now you can create an ensemble with as many nodes as you want by making a few changes.
6. Lunch Zookeeper on each nodes
Right now, your configuration is not ready on your Zookeeper Cluster. Indeed, we need to install Spark and to configure it with those Zookeeper nodes.
Even if you do not have install spark yet, you can launch zookeeper. Go on the Bin directory and execute this command on each nodes : ./zkServer.sh Start
Conclusion : Your quorum of 3 nodes with Zookeeper is now ready. The next step is to install Apache-Spark.
You can follow my tutorial : How to install and configure Apache-Spark